Publications
2026
[ICML 2026] Can Large Language Models Generalize Procedures Across Representations?
My new paper accepted at ICML 2026!
TL;DR: LLMs do not naively generalize procedures across representations, but successful generalization has analogical patterns.
Large language models (LLMs) are trained and tested extensively on symbolic representations such as code and graphs, yet real-world user tasks are often specified in natural language. To what extent can LLMs generalize across these representations? Here, we approach this question by studying isomorphic tasks involving procedures represented in code, graphs, and natural language (e.g., scheduling steps in planning). We find that training LLMs with popular post-training methods on graphs or code data alone does not reliably generalize to corresponding natural language tasks, while training solely on natural language can lead to inefficient performance gains. To address this gap, we propose a two-stage data curriculum that first trains on symbolic, then natural language data. The curriculum substantially improves model performance across model families and tasks. Remarkably, a 1.5B Qwen model trained by our method can closely match zero-shot GPT-4o in naturalistic planning. Finally, our analysis suggests that successful cross-representation generalization can be interpreted as a form of generative analogy, which our curriculum effectively encourages.
2025
[ACL 2025 main] One Language, Many Gaps: Evaluating Dialect Fairness and Robustness of Large Language Models in Reasoning Tasks
My internship project with MSR!
TL;DR: LLMs exhibit significant unfairness and brittleness to reasoning prompts expressed in dialects.
1. Focusing on African American Vernacular English (AAVE), we present the first study on LLMs’ fairness and robustness to a dialect in canonical reasoning tasks (algorithm, math, logic, and comprehensive reasoning).
2. We hire AAVE speakers, including experts with computer science backgrounds, to rewrite seven popular benchmarks, such as HumanEval and GSM8K. The result of this effort is ReDial, a dialectal benchmark comprising 1.2K+ parallel query pairs in Standardized English and AAVE.
3. We use ReDial to evaluate state-of-the-art LLMs, including GPT4o/4/3.5-turbo, LLaMA-3.1/3, Mistral, and Phi-3. We find that, compared to Standardized English, almost all of these widely used models show significant brittleness and unfairness to queries in AAVE.
4. Furthermore, AAVE queries can degrade performance more substantially than misspelled texts in Standardized English, even when LLMs are more familiar with the AAVE queries.
5. Finally, asking models to rephrase questions in Standardized English does not close the performance gap but generally introduces higher costs.
6. Overall, our findings indicate that LLMs provide unfair service to dialect users in complex reasoning tasks.
2024
[ICML 2024] Graph-enhanced Large Language Models in Asynchronous Plan Reasoning
My first project in DPhil! Very excited to have collaborated with fantastic researchers!
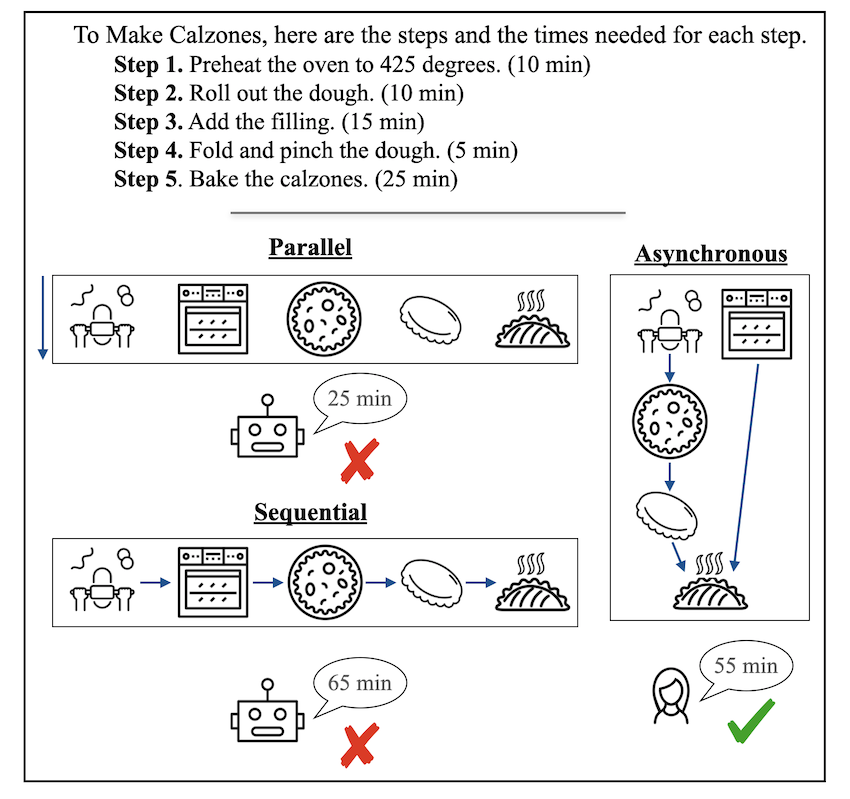
TL;DR: Off-the-shelf graph prompting consistently improves LLM performance in asynchronous planning.
1. We automatically generate and open-source a high-quality dataset for asynchronous planning which requires both sequential and parallel efficient sheduling.
2. We find that LLMs are extremely poor when they are not supplied with detailed task illustrations for efficient asynchronous planning.
3. We propose an off-the-shelf prompting method Plan Like a Graph (PLaG) and we show that PLaG consistently boosts SOTA model performance over all complexity levels.
4. Despite the performance boost, we still find that LLMs tend to suffer from severe degradataion with increasing task complexities, which highlights the limitations of using LLMs to simulate digital devices.
2024
[LREC-COLING 2024] Probing Large Language Models for Scalar Adjective Lexical Semantics and Scalar Diversity Pragmatics
A short version of my master thesis!.
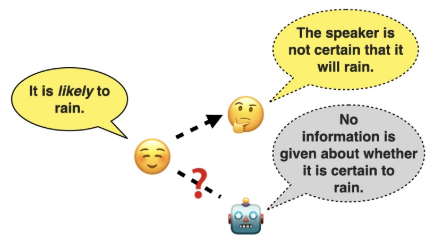
TL;DR: LLMs are quite good at scalar adjective lexical semantics but not at scalar diversity pragmatics.
Scalar adjectives pertain to various domain scales and vary in intensity within each scale (e.g. certain is more intense than likely on the likelihood scale). Scalar implicatures arise from the consideration of alternative statements which could have been made. They can be triggered by scalar adjectives and require listeners to reason pragmatically about them. Some scalar adjectives are more likely to trigger scalar implicatures than others. This phenomenon is referred to as scalar diversity. In this study, we probe different families of Large Language Models such as GPT-4 for their knowledge of the lexical semantics of scalar adjectives and one specific aspect of their pragmatics, namely scalar diversity. We find that they encode rich lexical-semantic information about scalar adjectives. However, the rich lexical-semantic knowledge does not entail a good understanding of scalar diversity. We also compare current models of different sizes and complexities and find that larger models are not always better. Finally, we explain our probing results by leveraging linguistic intuitions and model training objectives.